【并发编程】线程基础
一. 实现线程的方式
1. 为何说只有一种实现线程的方式
1.1 常见的实现线程的方式
1.1.1 继承Thread类
继承 Thread 类,并重写其中的 run() 方法。
public class DemoThread extends Thread {
@Override
public void run() {
System.out.println('用Thread类实现线程');
}
}1.1.2 实现 Runnable 接口
实现 Runnable 接口,实现其 run() 方法,然后将实现了 Runnable 接口的实例传递到 Thread 类中就可以实现多线程。
public class RunnableThread implements Runnable {
@Override
public void run() {
System.out.println('用实现Runnable接口实现线程');
}
}1.1.3 线程池创建线程
通过线程池来创建线程。线程中实现了很多线程,我们可以通过其构造器指定该线程池允许创建的线程的最大数量;比如:我们将线程池的数量设置为10,那么就将会有10个子线程来为我们工作。接下来,我们通过线程池中的代码来看看线程池是怎么创建线程的。
static class DefaultThreadFactory implements ThreadFactory {
DefaultThreadFactory() {
SecurityManager s = System.getSecurityManager();
group = (s != null) ? s.getThreadGroup() :
Thread.currentThread().getThreadGroup();
namePrefix = "pool-" +
poolNumber.getAndIncrement() +
"-thread-";
}
public Thread newThread(Runnable r) {
Thread t = new Thread(group, r,
namePrefix + threadNumber.getAndIncrement(),
0);
if (t.isDaemon())
t.setDaemon(false);
if (t.getPriority() != Thread.NORM_PRIORITY)
t.setPriority(Thread.NORM_PRIORITY);
return t;
}
}对于线程池而言,本质上是通过线程工厂来创建线程的,默认采用 DefaultThreadFactory,它会给线程池创建的线程设置一些默认值,比如:线程的名字、是否是守护线程、线程的优先级等;最终还是通过 new Thread() 来创建线程,只是构造方法中传入的参数多一些。
1.1.4 有返回值的 Callable 创建线程
Runnable 创建的线程时没有返回值的,而 Callable 和与之相关的 Future 和 FutureTask 可以把线程执行的结果作为返回值返回。如代码所示:实现 Callable 接口,并且泛型设置为 Integer ,然后返回一个随机整数。
class CallableTask implements Callable<Integer> {
@Override
public Integer call() throws Exception {
return new Random().nextInt();
}
}
//创建线程池
ExecutorService service = Executors.newFixedThreadPool(10);
//提交任务,并用 Future提交返回结果
Future<Integer> future = service.submit(new CallableTask());无论是 Callable 还是 FutureTask ,它们首先和 Runnable 一样都是一个任务,是需要被执行的,而不是说它们本身就是一个线程。它们可以放到线程池中执行:如代码所示,submit() 方法把任务放到线程池中,并由线程池创建线程。
1.2 总结,为什么实现线程只有一种方式
根据前面的实现线程的方式,我们可以看到比如线程池、定时器等仅仅只是在 new Thread() 之外做了一层封装;最终都还是通过实现 Runnable 接口或者继承 Thread 类来实现的。
我们知道,启动线程的方式是调用 start() 方法,然后在 start() 方法中最终会调 run() 方法。
我们来看 Thread 类的时候可以发现,在 Thread 类的 run() 方法中做了如下操作: 判断 target 不为 null 的情况下,调用 target 的 run() 方法;而 target 实际上就是 Runnable 接口的一个实例,即使用 Runnable 接口实现线程时传给Thread类的对象。
继承 Thread 类,然后重写 run() 方法,重写后的run()方法中就是需要执行的任务,最终还是调用 start() 方法来启动线程。
所以创建线程就只有一种方式,就是构造一个 Thread 类,这是创建线程的唯一方式。
上面看到的实现线程的两种方式本质上都是一样的,就是构造一个 Thread 类,不同点在于实现线程运行内容的不同 :要买来自重写的 run() 方法,要么来自 target 的 run() 方法。
所以我们可以这样描述:
本质上,实现线程只有一种方式,而要想实现线程执行的内容,却有两种方式,也就是可以通过 实现 Runnable 接口的方式,或是继承 Thread 类重写 run() 方法的方式,把我们想要执行的代码传入,让线程去执行,在此基础上,如果我们还想有更多实现线程的方式,比如线程池和 Timer 定时器,只需要在此基础上进行封装即可。
2. 为什么说实现 Runnable 接口比继承 Thread 类实现线程要好
我们来总结一下实现 Runnable 接口比继承 Thread 类实现线程好在哪里?
- 从代码架构考虑:
Runnable接口只有一个run()方法,它定义了需要执行的内容,在这种情况些 实现了Runnable类和Thread类的解耦;Thread类负责启动线程和设置属性等,权责分明。 - 从性能考虑:使用继承
Thread类来实现线程,没执行依次任务,就需要创建一个独立的线程;执行完成之后到生命周期的尽头,如果需要再次执行,就必须重新创建一个线程;在线程执行的任务量比较大的时候,带来的开销也很大。如果使用实现Runnable接口的方式来实现线程,就可以把任务直接传入线程池,使用一些固定的线程来完成任务,不需要每次新建/销毁线程,大大降低了性能开销。 - 从拓展性考虑:Java 语言不执行多继承,如果类一旦继承了
Thread类,那么后续就不能继承其他的类。如果该类需要继承其他的一些类来实现功能上的拓展,就显得很局限了,限制了代码的拓展性。而Java运行多实现,则实现Runnable接口方式来实现线程,则不会限制代码的拓展性。
综上所述:
应该优先选择通过实现 Runnable 接口的方式来创建线程。
二. 如何正确停止线程
通长情况下,我们不会停止一个线程,而是允许线程运行到结束,然后让它自然停止。但是依然也有许多特殊情况需要手动停止线程,比如:用户突然关闭程序,程序出错重启等。
1. 正确停止线程
对于Java 程序而言,最正确的停止线程的方式是 interrupt,但 interrupt 仅仅起到通知被停止线程的作用。对于被停止线程而言,它完全具有自主权,可以选择立即停止 、过一会停止,或者不停止。那么为什么Java不提供强制停止线程的能力呢?
其实,Java 希望程序间能够相互通知,相互协作的管理线程,因为如果在不知道对方线程正在做的工作,贸然停止线程就可能造成一些安全问题,为了避免问题,就需要给对方线程一定的事件来处理收尾工作。
1.1 用 interrupt 停止线程
while (!Thread.currentThread().islnterrupted() && more work flag) {
//do more work
}一旦调用某个线程的 interrupt() 方法之后,这个线程的中断标记为就会被置为 true ;每个线程都有这样的标记位,当线程执行时,应该定期检查该标志位,如果标记为被置为 true ,就说明有程序想终止该线程。
在上面的代码中看到,在 while 循环体判断语句中,首先通过 Thread.currentThread().islnterrupted() 判断线程是否被中断,随后检查是否还有工作要做的标志位,两个条件都满足的情况下,才会继续执行下面的工作。
eg:
public class StopThread implements Runnable {
@Override
public void run() {
int count = 0;
while (!Thread.currentThread().isInterrupted() && count < 1000) {
System.out.println("count = " + count++);
}
}
public static void main(String[] args) throws InterruptedException {
Thread thread = new Thread(new StopThread());
thread.start();
Thread.sleep(5);
thread.interrupt();
}
}在 StopThread 类的 run() 方法中,首先判断线程是否被中断,然后判断 count 是否小于 1000。这线程的工作内容就是打印0~999的数字,每打印一个数字,count 加 1 ;可以看到每次开始之前都会检查线程是否被中断。
在 main 函数中启动该线程,然后过 5 毫秒之后立刻终止线程,该线程会检测中断信号,于是在线程未执行完就会停止,这种就属于通过 interrupt 正确停止线程的情况。
1.2 sleep 期间能否感受到中断
现在我们考虑一种特殊情况:在线程执行过程中有休眠需求,也就是每打印一次,进入一次 sleep ,将 sleep 时间设置为 10 秒;则改造后的代码如下
Runnable runnable = () -> {
int num = 0;
try {
while (!Thread.currentThread().isInterrupted() &&
num <= 1000) {
System.out.println(num);
num++;
Thread.sleep(10000);
}
} catch (InterruptedException e) {
e.printStackTrace();
}
};public class StopDuringSleep {
public static void main(String[] args) throws InterruptedException {
Runnable runnable = () -> {
int num = 0;
try {
while (!Thread.currentThread().isInterrupted() && num <= 1000) {
System.out.println(num);
num++;
Thread.sleep(1000000);
}
} catch (InterruptedException e) {
e.printStackTrace();
}
};
Thread thread = new Thread(runnable);
thread.start();
Thread.sleep(5);
thread.interrupt();
}
}在主线程休眠 5 毫秒后,通知子线程中断,此时子线程仍然在执行 sleep 语句,处于休眠中。那么就需要考虑,在休眠中的线程能否感受到中断通知呢?如果需要等到线程休眠结束后,那岂不响应中断太不及时了。
在 Java 设计之初,如果 sleep,wait 等可以让线程进入阻塞的方法使得线程休眠了,而处于休眠中的线程被中断,那么线程是可以感受到中断信号的,并且会抛出一个 InterruptedException 异常,同时清除中断信号,将中断标记为置为false;这样,就不用担心长时间休眠中的线程感受不到中断了,因为即便现在还在休眠中,仍然能够响应中断通知,并抛出异常。
1.3 相应中断的两种最佳处理方式
在实际开发中肯定是团队协作的,不同的人负责编写不同的方法,然后相互调用来实现整个业务的逻辑。那么如果我们负责编写的方法需要被别人调用,同时我们的方法内调用了 sleep 或者 wait 等能响应中断的方法时,仅仅 catch 住异常是不够的。
private void subTas() {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
// 在这里不处理该异常是非常不好的
}
}我们可以在方法中使用 try/catch 或在方法签名中声明 throws InterruptedException。
1.3.1 方法签名抛异常,run() 强制 try/catch
上面代码所示 catch 语句块里是空的,并没有进行任何处理。假设线程执行到这个方法,并且正在 sleep ,此时有线程发送 interrupt 通知试图中断线程,就会抛出异常,并清除中断信号。抛出的异常被 catch 语句块捕捉。
但是,捕捉到异常的 catch 没有进行任何处理逻辑,相当于把中断信号给隐藏了,这样做是很不合理的。我们可以选择在方法签名中抛出异常
void subTask2() throws InterruptedException {
Thread.sleep(1000);
}正如代码所示:要求每一个方法的调用方有义务去处理异常。调用方要不使用 try/catch 并在 catch 中正确处理异常,要不将异常声明到方法签名中。如果每层逻辑都遵守规范,便可以将中断信号传递到顶层,最终让 run() 方法可以捕获异常。对于 run() 方法而言,它本身没有抛出异常的能力,只能通过 try/catch 来处理异常;可以根据不同的业务逻辑来进行相应的处理。
1.3.2 再次中断
private void reInterrupt() {
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
Thread.currentThread().interrupt();
e.printStackTrace();
}
}除了刚刚推荐的将异常声明到方法签名中的方式以外,还可以在 catch 语句中再次中断线程。如代码所示,需要在 catch 语句块中调用 Thread.currentThread().interrupt()函数。因为如果线程在休眠期间被中断,那么会自动清除中断信号。如果这时候手动添加中断信号,中断信号依然可以被捕捉到。这样后续执行的方法依然可以检测到这里发生过中断,可以做出相应的处理,整个线程可以正常退出
2. 为什么 volatile 标记位的停止方法是错误的?
2.1 错误的停止方法
首先,我们来看几种线程停止的错误的方法:比如:stop() , suspend() 和 resume(),这些方法已经被 Java 标记为 @Deprecated。我们不应该再使用它们。因为 stop() 会直接把线程停止,这样就没有给足够的事件来处理想要在停止之前保存数据的逻辑,任务嘎然而止,会导致出现数据完整性等问题。
对于 suspend() 和 resume() 而言,它们的问题在于如果线程调用 suspend() ,它并不会释放锁,就开始进入休眠,但此时有可能扔持有锁,这样就容易导致死锁,因为这把锁在线程被 resume() 之前,是不会释放的。
正因为有这样的风险,所以 suspend() 和 resume() 组合使用的方式也被废弃了。
接下来我们来看一下,为什么用 volatile 标记位的停止方法也是错误的?
2.2 volatile 修饰标记位使用的场景
public class VolatileCanStop implements Runnable {
private volatile boolean canceled = false;
@Override
public void run() {
int num = 0;
try {
while (!canceled && num <= 1000000) {
if (num % 10 == 0) {
System.out.println(num + "是10的倍数。");
}
num++;
Thread.sleep(1);
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public static void main(String[] args) throws InterruptedException {
VolatileCanStop r = new VolatileCanStop();
Thread thread = new Thread(r);
thread.start();
Thread.sleep(3000);
r.canceled = true;
}
}如代码所示:声明了一个叫做 VolatileStopThread 的类,它实现了 Runnable 接口,然后在 run() 中进行 while 循环,在循环体中进行了两层判断,首先判断 canceled 变量的值(canceled 变量是一个被 volatile 修饰的初始值为 false 的布尔值),当该值变为 true 时,while 跳出循环,while 第二个判断是 num 值小于 1000000 ,在 while 循环体中,只要是10的倍数,就打印出来,然后 num++ 。
接下来,在 main() 方法中,首先启动线程,然后经过3秒中的时间, 把用 volatile 修饰的布尔值标记位设置为 true,这样,正在运行的线程就会在下一次 while 循环判断中判断出 canceled 的值已经变为 true 了,这样就不再满足 while 的判断条件,跳出整个 while 循环,线程就停止了,这种情况是演示 volatile 修饰的标记位可以正常工作的情况。
2.3 volatile 修饰标记位不适用的场景
class Producer implements Runnable {
public volatile boolean canceled = false;
BlockingQueue storage;
public Producer(BlockingQueue storage) {
this.storage = storage;
}
@Override
public void run() {
int num = 0;
try {
while (num <= 100000 && !canceled) {
if (num % 50 == 0) {
storage.put(num);
System.out.println(num + "是50的倍数,被放到仓库中了。");
}
num++;
}
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
System.out.println("生产者结束运行");
}
}
}首先,声明了一个生产者 Producer ,通过 volatile 标记的初始值为 false 的布尔值 canceled 来停止线程。在 run() 方法中, while 的判断语句是 num 是否小于 100000 以及 canceled 是否被标记。while 循环体中判断 num 如果是 50 的倍数就放到 storage 仓库中 ,storage 是生产者与消费者质检通信的存储器,当 num 大于 100000 或被通知停止时,会跳出 while 循环并执行 finally 语句块,告诉大家 『生产者结束运行』
class Consumer {
BlockingQueue storage;
public Consumer(BlockingQueue storage) {
this.storage = storage;
}
public boolean needMoreNums() {
if (Math.random() > 0.97) {
return false;
}
return true;
}
}对于消费者 Consumer ,它与生产者共用同一个仓库 storage ,并且在方法内通过 needMoreNums() 方法判断是否需要继续使用更多的数字,刚才生产者生产了一些 50 的倍数供消费者使用,消费者是否继续使用数字的判断条件时产生一个随机数并与 0.97 进行比较,大于 0.97 就不在继续使用数字。
public static void main(String[] args) throws InterruptedException {
ArrayBlockingQueue storage = new ArrayBlockingQueue(8);
Producer producer = new Producer(storage);
Thread producerThread = new Thread(producer);
producerThread.start();
Thread.sleep(500);
Consumer consumer = new Consumer(storage);
while (consumer.needMoreNums()) {
System.out.println(consumer.storage.take() + "被消费了");
Thread.sleep(100);
}
System.out.println("消费者不需要更多数据了。");
//一旦消费不需要更多数据了,我们应该让生产者也停下来,但是实际情况却停不下来
producer.canceled = true;
System.out.println(producer.canceled);
}
}在 main() 函数中,首先创建了生产者/消费者共用的仓库 BlockingQueue storage,仓库容量是 8,并且建立生产者并将生产者放入线程后启动线程,启动后进行 500 毫秒的休眠,这是生产者会阻塞, 500 毫秒后消费者被创建出来,并判断是否需要更多的数字,然后每次消费后休眠 100 毫秒,这样的业务逻辑是有可能出现在实际生产中的。
当消费者不再需要数据,就会将 canceled 的标记位设置为 true ,理论上此时生产者就会跳出 while 循环,并打印出 『 生产者运行结束』。
然而结果并不是我们想象的那样,尽管已经把 canceled 设置为 true , 但生产者仍然没有停止,这是因为在这种情况下,生产者在执行 storage.put(num) 时发生阻塞,在它被唤醒之前是没办法进入下一次循环判断 canceled 的值的,所以这种情况下用 volatile 是没有办法让生产者停下来的,相反如果用 interrupt 语句来中断,即便生产者处理阻塞状态,仍然能够感受到中断信号,并做响应处理。
三. 线程的6中状态的切换
1. 线程的6中状态
在 Java 中线程的生命周期中一共有6种状态
- New(新建)
- Runnable(可运行)
- Blocked(被阻塞)
- Waiting(等待)
- Timed Waiting(计时等待)
- Terminated (被终止)
如果想要确定线程当前的状态,可以通过 getState() 方法,并且线程在任何时刻只可能处于 1 种状态。
下面我们来逐个介绍线程的 6 种状态:
1.1 New 新创建
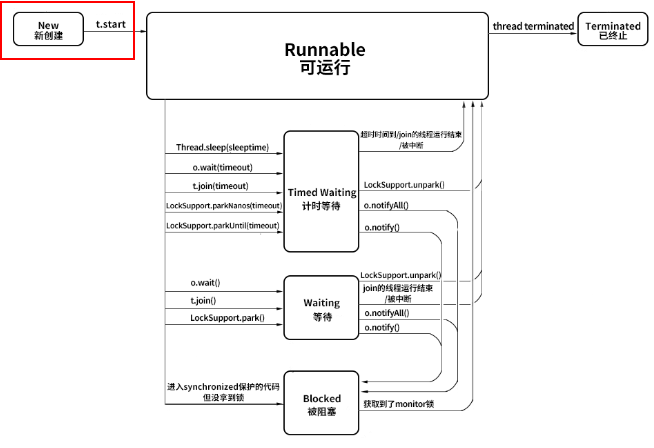
New 表示线程被创建但尚未启动的状态:当我们用 new Thread() 新建一个线程时,如果线程没有开始运行 start() 方法,所以也没有开始执行 run() 方法里面的代码,那么此时它的状态就是 New。而一旦线程调用了 start(),它的状态就会从 New 变成 Runnable状态。
1.2 Runnable 可运行
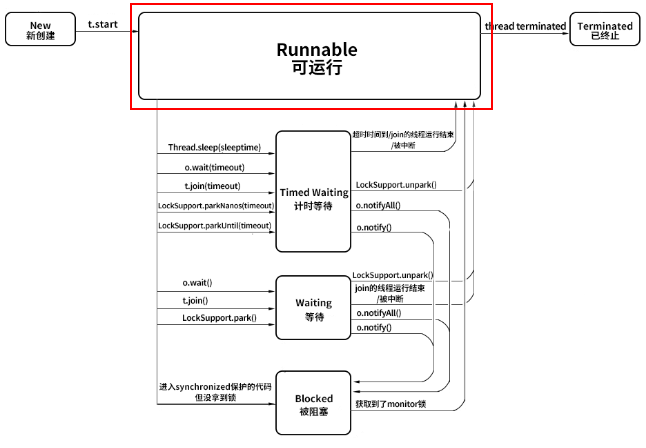
Java 中的 Runable 状态对应操作系统线程状态中的两种状态,分别是 Running 和 Ready,也就是说,Java 中处于 Runnable 状态的线程有可能正在执行,也有可能没有正在执行,正在等待被分配 CPU 资源。
所以,如果一个正在运行的线程是 Runnable 状态,当它运行到任务的一半时,执行该线程的 CPU 被调度去做其他事情,导致该线程暂时不运行,它的状态依然不变,还是 Runnable,因为它有可能随时被调度回来继续执行任务。
1.3 Blocked 阻塞状态
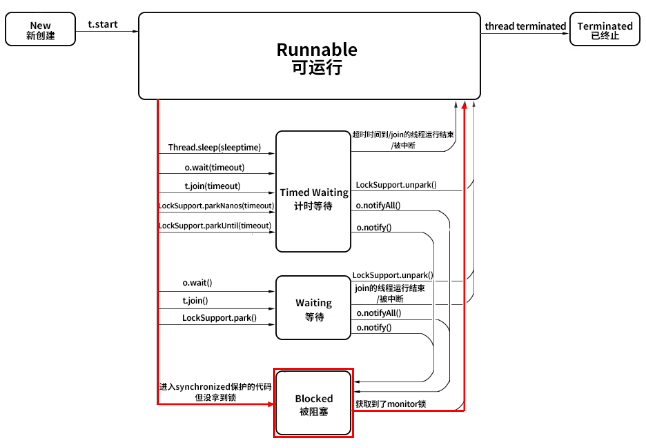
从 Runnable 状态进入 Blocked 状态只有一种可能,就是进入 synchronized 保护的代码时没有抢到 monitor 锁,无论是进入 synchronized 代码块,还是 synchronized 方法;当处于 Blocked 的线程抢到 monitor 锁,就会从 Blocked 状态回到Runnable 状态。
1.4 Waiting 等待
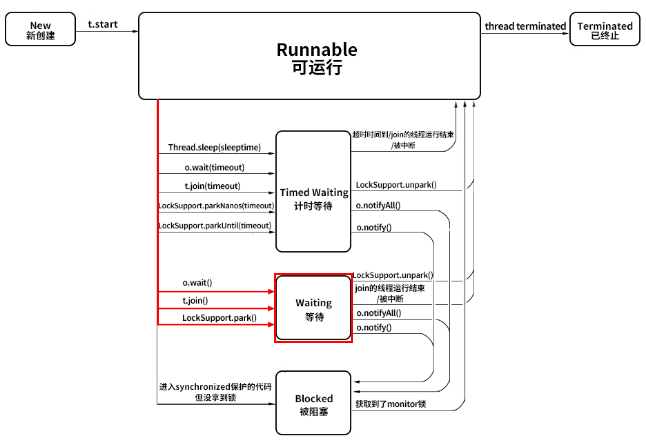
线程进入 Waiting 状态有三种可能性。
- 没有设置 Timeout 参数的 Object.wait() 方法。
- 没有设置 Timeout 参数的 Thread.join() 方法。
- LockSupport.park() 方法。
刚才强调过,Blocked 仅仅针对 synchronized monitor 锁,可是在 Java 中还有很多其他的锁,比如 ReentrantLock,如果线程在获取这种锁时没有抢到该锁就会进入 Waiting 状态,因为本质上它执行了 LockSupport.park() 方法,所以会进入 Waiting 状态。同样,Object.wait() 和 Thread.join() 也会让线程进入 Waiting 状态。
Blocked 与 Waiting 的区别是 Blocked 在等待其他线程释放 monitor 锁,而 Waiting 则是在等待某个条件,比如 join 的线程执行完毕,或者是 notify()/notifyAll() 。
1.5 Timed Waiting 限期等待
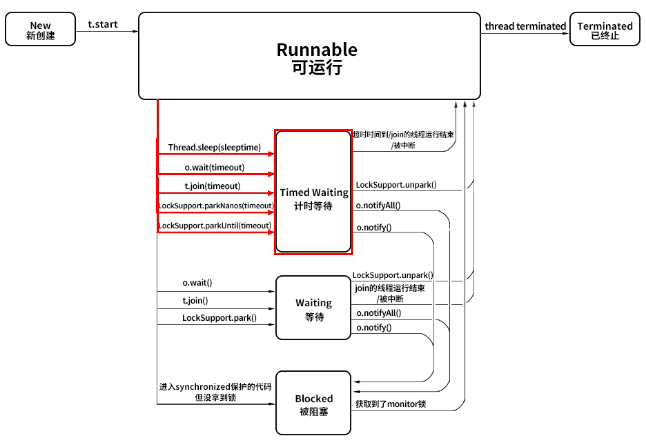
在 Waiting 上面是 Timed Waiting 状态,这两个状态是非常相似的,区别仅在于有没有时间限制,Timed Waiting 会等待超时,由系统自动唤醒,或者在超时前被唤醒信号唤醒。
以下情况会让线程进入 Timed Waiting 状态。
- 设置了时间参数的 Thread.sleep(long millis) 方法;
- 设置了时间参数的 Object.wait(long timeout) 方法;
- 设置了时间参数的 Thread.join(long millis) 方法;
- 设置了时间参数的 LockSupport.parkNanos(long nanos) 方法和 LockSupport.parkUntil(long deadline) 方法。
如果其他线程调用 notify() 或 notifyAll()来唤醒它,它会直接进入 Blocked 状态,这是为什么呢?因为唤醒 Waiting 线程的线程如果调用 notify() 或 notifyAll(),要求必须首先持有该 monitor 锁,所以处于 Waiting 状态的线程被唤醒时拿不到该锁,就会进入 Blocked 状态,直到执行了 notify()/notifyAll() 的唤醒它的线程执行完毕并释放 monitor 锁,才可能轮到它去抢夺这把锁,如果它能抢到,就会从 Blocked 状态回到 Runnable 状态。
同样在 Timed Waiting 中执行 notify() 和 notifyAll() 也是一样的道理,它们会先进入 Blocked 状态,然后抢夺锁成功后,再回到 Runnable 状态。
当然对于 Timed Waiting 而言,如果它的超时时间到了且能直接获取到锁/join的线程运行结束/被中断/调用了LockSupport.unpark(),会直接恢复到 Runnable 状态,而无需经历 Blocked 状态。
1.6 Terminated 终止
要想进入这个Terminated 终止状态有两种可能。
run() 方法执行完毕,线程正常退出。
出现一个没有捕获的异常,终止了 run() 方法,最终导致意外终止。
注意点
最后我们再看线程转换的两个注意点。
- 线程的状态是需要按照箭头方向来走的,比如线程从 New 状态是不可以直接进入 Blocked 状态的,它需要先经历 Runnable 状态。
- 线程生命周期不可逆:一旦进入 Runnable 状态就不能回到 New 状态;一旦被终止就不可能再有任何状态的变化。所以一个线程只能有一次 New 和 Terminated 状态,只有处于中间状态才可以相互转换。
四. wait/notify/notifyAll 方法的使用注意事项
从以下三个问题入手学习 wait/notify/notifyAll 方法的使用注意事项:
- 为什么 wait 方法必须在 synchronized 保护的同步代码中使用?
- 为什么 wait/notify/notifyAll 被定义在 Object 类中,而 sleep 定义在 Thread 类中?
- wait/notify 和 sleep 方法的异同?
1. 为什么 wait 方法必须在 synchronized 保护的同步代码中使用?
首先,我们来看看 wait 方法的源码注释是怎么写的。
“wait method should always be used in a loop:
synchronized (obj) {
while (condition does not hold)
obj.wait();
... // Perform action appropriate to condition
}This method should only be called by a thread that is the owner of this object’s monitor.”
意思是说,在使用 wait 方法时,必须把 wait 方法写在 synchronized 保护的 while 代码块中,并始终判断执行条件是否满足,如果满足就往下继续执行,如果不满足就执行 wait 方法,而在执行 wait 方法之前,必须先持有对象的 monitor 锁,也就是通常所说的 synchronized 锁。那么设计成这样有什么好处呢?
我们逆向思考这个问题,如果不要求 wait 方法放在 synchronized 保护的同步代码中使用,而是可以随意调用,那么就有可能写出这样的代码。
class BlockingQueue {
Queue<String> buffer = new LinkedList<String>();
public void give(String data) {
buffer.add(data);
notify(); // Since someone may be waiting in take
}
public String take() throws InterruptedException {
while (buffer.isEmpty()) {
wait();
}
return buffer.remove();
}
}在代码中可以看到有两个方法,give 方法负责往 buffer 中添加数据,添加完之后执行 notify 方法来唤醒之前等待的线程,而 take 方法负责检查整个 buffer 是否为空,如果为空就进入等待,如果不为空就取出一个数据,这是典型的生产者消费者的思想。
但是这段代码并没有受 synchronized 保护,于是便有可能发生以下场景:
- 首先,消费者线程调用 take 方法并判断 buffer.isEmpty 方法是否返回 true,若为 true 代表buffer是空的,则线程希望进入等待,但是在线程调用 wait 方法之前,就被调度器暂停了,所以此时还没来得及执行 wait 方法。
- 此时生产者开始运行,执行了整个 give 方法,它往 buffer 中添加了数据,并执行了 notify 方法,但 notify 并没有任何效果,因为消费者线程的 wait 方法没来得及执行,所以没有线程在等待被唤醒。
- 此时,刚才被调度器暂停的消费者线程回来继续执行 wait 方法并进入了等待。
虽然刚才消费者判断了 buffer.isEmpty 条件,但真正执行 wait 方法时,之前的 buffer.isEmpty 的结果已经过期了,不再符合最新的场景了,因为这里的“判断-执行”不是一个原子操作,它在中间被打断了,是线程不安全的。
假设这时没有更多的生产者进行生产,消费者便有可能陷入无穷无尽的等待,因为它错过了刚才 give 方法内的 notify 的唤醒。
我们看到正是因为 wait 方法所在的 take 方法没有被 synchronized 保护,所以它的 while 判断和 wait 方法无法构成原子操作,那么此时整个程序就很容易出错。
我们把代码改写成源码注释所要求的被 synchronized 保护的同步代码块的形式,代码如下:
public void give(String data) {
synchronized (this) {
buffer.add(data);
notify();
}
}
public String take() throws InterruptedException {
synchronized (this) {
while (buffer.isEmpty()) {
wait();
}
return buffer.remove();
}
}这样就可以确保 notify 方法永远不会在 buffer.isEmpty 和 wait 方法之间被调用,提升了程序的安全性。
另外,wait 方法会释放 monitor 锁,这也要求我们必须首先进入到 synchronized 内持有这把锁。
这里还存在一个“虚假唤醒”(spurious wakeup)的问题,线程可能在既没有被notify/notifyAll,也没有被中断或者超时的情况下被唤醒,这种唤醒是我们不希望看到的。虽然在实际生产中,虚假唤醒发生的概率很小,但是程序依然需要保证在发生虚假唤醒的时候的正确性,所以就需要采用while循环的结构。
while (condition does not hold)
obj.wait();这样即便被虚假唤醒了,也会再次检查while里面的条件,如果不满足条件,就会继续wait,也就消除了虚假唤醒的风险。
2. 为什么 wait/notify/notifyAll 被定义在 Object 类中,而 sleep 定义在 Thread 类中?
为什么 wait/notify/notifyAll 方法被定义在 Object 类中?而 sleep 方法定义在 Thread 类中?主要有两点原因:
- 因为 Java 中每个对象都有一把称之为 monitor 监视器的锁,由于每个对象都可以上锁,这就要求在对象头中有一个用来保存锁信息的位置。这个锁是对象级别的,而非线程级别的,wait/notify/notifyAll 也都是锁级别的操作,它们的锁属于对象,所以把它们定义在 Object 类中是最合适,因为 Object 类是所有对象的父类。
- 因为如果把 wait/notify/notifyAll 方法定义在 Thread 类中,会带来很大的局限性,比如一个线程可能持有多把锁,以便实现相互配合的复杂逻辑,假设此时 wait 方法定义在 Thread 类中,如何实现让一个线程持有多把锁呢?又如何明确线程等待的是哪把锁呢?既然我们是让当前线程去等待某个对象的锁,自然应该通过操作对象来实现,而不是操作线程。
3. wait/notify 和 sleep 方法的异同
对比 wait/notify 和 sleep 方法的异同,主要对比 wait 和 sleep 方法,我们先说相同点:
它们都可以让线程阻塞。
它们都可以响应 interrupt 中断:在等待的过程中如果收到中断信号,都可以进行响应,并抛出 InterruptedException 异常。
但是它们也有很多的不同点:
- wait 方法必须在 synchronized 保护的代码中使用,而 sleep 方法并没有这个要求。
- 在同步代码中执行 sleep 方法时,并不会释放 monitor 锁,但执行 wait 方法时会主动释放 monitor 锁。
- sleep 方法中会要求必须定义一个时间,时间到期后会主动恢复,而对于没有参数的 wait 方法而言,意味着永久等待,直到被中断或被唤醒才能恢复,它并不会主动恢复。
- wait/notify 是 Object 类的方法,而 sleep 是 Thread 类的方法。
五. 有哪几种实现生产者消费者模式的方法
5.1 生产者消费者模式
我们先来看看什么是生产者消费者模式,生产者消费者模式是程序设计中非常常见的一种设计模式,被广泛运用在解耦、消息队列等场景。在现实世界中,我们把生产商品的一方称为生产者,把消费商品的一方称为消费者,有时生产者的生产速度特别快,但消费者的消费速度跟不上,俗称“产能过剩”,又或是多个生产者对应多个消费者时,大家可能会手忙脚乱。如何才能让大家更好地配合呢?这时在生产者和消费者之间就需要一个中介来进行调度,于是便诞生了生产者消费者模式。
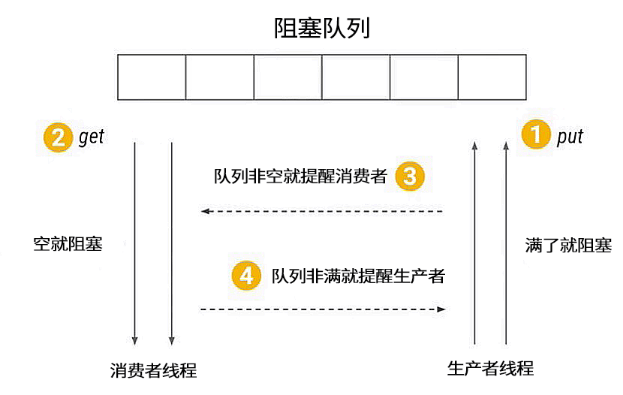
使用生产者消费者模式通常需要在两者之间增加一个阻塞队列作为媒介,有了媒介之后就相当于有了一个缓冲,平衡了两者的能力,整体的设计如图所示,最上面是阻塞队列,右侧的 1 是生产者线程,生产者在生产数据后将数据存放在阻塞队列中,左侧的 2 是消费者线程,消费者获取阻塞队列中的数据。而中间的 3 和 4 分别代表生产者消费者之间互相通信的过程,因为无论阻塞队列是满还是空都可能会产生阻塞,阻塞之后就需要在合适的时机去唤醒被阻塞的线程。
那么什么时候阻塞线程需要被唤醒呢?有两种情况:
- 第一种情况是当消费者看到阻塞队列为空时,开始进入等待,这时生产者一旦往队列中放入数据,就会通知所有的消费者,唤醒阻塞的消费者线程。
- 另一种情况是如果生产者发现队列已经满了,也会被阻塞,而一旦消费者获取数据之后就相当于队列空了一个位置,这时消费者就会通知所有正在阻塞的生产者进行生产。
5.2 如何用 BlockingQueue 实现生产者消费者模式
我们接下来看如何用 wait/notify/Condition/BlockingQueue 实现生产者消费者模式,先从最简单的 BlockingQueue 开始讲起:
public static void main(String[] args) {
BlockingQueue<Object> queue = new ArrayBlockingQueue<>(10);
Runnable producer = () -> {
while (true) {
queue.put(new Object());
}
};
new Thread(producer).start();
new Thread(producer).start();
Runnable consumer = () -> {
while (true) {
queue.take();
}
};
new Thread(consumer).start();
new Thread(consumer).start();
}如代码所示,首先,创建了一个 ArrayBlockingQueue 类型的 BlockingQueue,命名为 queue 并将它的容量设置为 10;其次,创建一个简单的生产者,while(true) 循环体中的queue.put() 负责往队列添加数据;然后,创建两个生产者线程并启动;同样消费者也非常简单,while(true) 循环体中的 queue.take() 负责消费数据,同时创建两个消费者线程并启动。为了代码简洁并突出设计思想,代码里省略了 try/catch 检测,我们不纠结一些语法细节。以上便是利用 BlockingQueue 实现生产者消费者模式的代码。虽然代码非常简单,但实际上 ArrayBlockingQueue 已经在背后完成了很多工作,比如队列满了就去阻塞生产者线程,队列有空就去唤醒生产者线程等。
5.3 如何用 Condition 实现生产者消费者模式
BlockingQueue 实现生产者消费者模式看似简单,背后却暗藏玄机,我们在掌握这种方法的基础上仍需要掌握更复杂的实现方法。我们接下来看如何在掌握了 BlockingQueue 的基础上利用 Condition 实现生产者消费者模式,它们背后的实现原理非常相似,相当于我们自己实现一个简易版的 BlockingQueue:
public class MyBlockingQueueForCondition {
private Queue queue;
private int max = 16;
private ReentrantLock lock = new ReentrantLock();
private Condition notEmpty = lock.newCondition();
private Condition notFull = lock.newCondition();
public MyBlockingQueueForCondition(int size) {
this.max = size;
queue = new LinkedList();
}
public void put(Object o) throws InterruptedException {
lock.lock();
try {
while (queue.size() == max) {
notFull.await();
}
queue.add(o);
notEmpty.signalAll();
} finally {
lock.unlock();
}
}
public Object take() throws InterruptedException {
lock.lock();
try {
while (queue.size() == 0) {
notEmpty.await();
}
Object item = queue.remove();
notFull.signalAll();
return item;
} finally {
lock.unlock();
}
}
}如代码所示,首先,定义了一个队列变量 queue 并设置最大容量为 16;其次,定义了一个 ReentrantLock 类型的 Lock 锁,并在 Lock 锁的基础上创建两个 Condition,一个是 notEmpty,另一个是 notFull,分别代表队列没有空和没有满的条件;最后,声明了 put 和 take 这两个核心方法。
因为生产者消费者模式通常是面对多线程的场景,需要一定的同步措施保障线程安全,所以在 put 方法中先将 Lock 锁上,然后,在 while 的条件里检测 queue 是不是已经满了,如果已经满了,则调用 notFull 的 await() 阻塞生产者线程并释放 Lock,如果没有满,则往队列放入数据并利用 notEmpty.signalAll() 通知正在等待的所有消费者并唤醒它们。最后在 finally 中利用 lock.unlock() 方法解锁,把 unlock 方法放在 finally 中是一个基本原则,否则可能会产生无法释放锁的情况。
下面再来看 take 方法,take 方法实际上是与 put 方法相互对应的,同样是通过 while 检查队列是否为空,如果为空,消费者开始等待,如果不为空则从队列中获取数据并通知生产者队列有空余位置,最后在 finally 中解锁。
这里需要注意,我们在 take() 方法中使用 while( queue.size() == 0 ) 检查队列状态,而不能用 if( queue.size() == 0 )。为什么呢?大家思考这样一种情况,因为生产者消费者往往是多线程的,我们假设有两个消费者,第一个消费者线程获取数据时,发现队列为空,便进入等待状态;因为第一个线程在等待时会释放 Lock 锁,所以第二个消费者可以进入并执行 if( queue.size() == 0 ),也发现队列为空,于是第二个线程也进入等待;而此时,如果生产者生产了一个数据,便会唤醒两个消费者线程,而两个线程中只有一个线程可以拿到锁,并执行 queue.remove 操作,另外一个线程因为没有拿到锁而卡在被唤醒的地方,而第一个线程执行完操作后会在 finally 中通过 unlock 解锁,而此时第二个线程便可以拿到被第一个线程释放的锁,继续执行操作,也会去调用 queue.remove 操作,然而这个时候队列已经为空了,所以会抛出 NoSuchElementException 异常,这不符合我们的逻辑。而如果用 while 做检查,当第一个消费者被唤醒得到锁并移除数据之后,第二个线程在执行 remove 前仍会进行 while 检查,发现此时依然满足 queue.size() == 0 的条件,就会继续执行 await 方法,避免了获取的数据为 null 或抛出异常的情况。
5.4 如何用 wait/notify 实现生产者消费者模式
最后我们再来看看使用 wait/notify 实现生产者消费者模式的方法,实际上实现原理和Condition 是非常类似的,它们是兄弟关系:
class MyBlockingQueue {
private int maxSize;
private LinkedList<Object> storage;
public MyBlockingQueue(int size) {
this.maxSize = size;
storage = new LinkedList<>();
}
public synchronized void put() throws InterruptedException {
while (storage.size() == maxSize) {
wait();
}
storage.add(new Object());
notifyAll();
}
public synchronized void take() throws InterruptedException {
while (storage.size() == 0) {
wait();
}
System.out.println(storage.remove());
notifyAll();
}
}如代码所示,最主要的部分仍是 take 与 put 方法,我们先来看 put 方法,put 方法被 synchronized 保护,while 检查队列是否为满,如果不满就往里放入数据并通过 notifyAll() 唤醒其他线程。同样,take 方法也被 synchronized 修饰,while 检查队列是否为空,如果不为空就获取数据并唤醒其他线程。使用这个 MyBlockingQueue 实现的生产者消费者代码如下:
/**
* 描述: wait形式实现生产者消费者模式
*/
public class WaitStyle {
public static void main(String[] args) {
MyBlockingQueue myBlockingQueue = new MyBlockingQueue(10);
Producer producer = new Producer(myBlockingQueue);
Consumer consumer = new Consumer(myBlockingQueue);
new Thread(producer).start();
new Thread(consumer).start();
}
}
class Producer implements Runnable {
private MyBlockingQueue storage;
public Producer(MyBlockingQueue storage) {
this.storage = storage;
}
@Override
public void run() {
for (int i = 0; i < 100; i++) {
try {
storage.put();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
class Consumer implements Runnable {
private MyBlockingQueue storage;
public Consumer(MyBlockingQueue storage) {
this.storage = storage;
}
@Override
public void run() {
for (int i = 0; i < 100; i++) {
try {
storage.take();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}以上就是三种实现生产者消费者模式的示例,其中,第一种 BlockingQueue 模式实现比较简单,但其背后的实现原理在第二种、第三种实现方法中得以体现,第二种、第三种实现方法本质上是我们自己实现了 BlockingQueue 的一些核心逻辑,供生产者与消费者使用。